The interaction and structure of mRNA, tRNA, RRNA - the three main nucleic acids - is considered by the science of cytology. It will help to find out what the role of transport (tRNA) is in cells. This very small, but at the same time undeniably important molecule takes part in the process of combining proteins that make up the body.
What is the structure of tRNA? It is very interesting to look at this substance “from the inside”, to find out its biochemistry and biological role. And also, how are the structure of tRNA and its role in protein synthesis interrelated?
What is tRNA, how is it structured?
Transport ribonucleic acid is involved in the construction of new proteins. Almost 10% of all ribonucleic acids are transport ones. To make it clear what chemical elements the molecule is formed from, we will describe the structure of the secondary structure of tRNA. Secondary structure considers all the basic chemical bonds between elements.
Consisting of a polynucleotide chain. The nitrogenous bases in it are connected by hydrogen bonds. Like DNA, RNA has 4 nitrogenous bases: adenine, cytosine, guanine, and uracil. In these compounds, adenine is always associated with uracil, and guanine, as usual, with cytosine.
Why does a nucleotide have the prefix ribo-? Simply, all linear polymers that have ribose instead of pentose at the base of the nucleotide are called ribonucleic. And transfer RNA is one of 3 types of just such a ribonucleic polymer.
Structure of tRNA: biochemistry
Let's look into the deepest layers of the molecule's structure. These nucleotides have 3 components:
- Sucrose, all types of RNA involve ribose.
- Phosphoric acid.
- Nitrogenous and pyrimidines.

Nitrogenous bases are connected to each other by strong bonds. It is customary to divide bases into purine and pyrimidine.
Purines are adenine and guanine. Adenine corresponds to an adenyl nucleotide of 2 interconnected rings. And guanine corresponds to the same “single-ring” guanine nucleotide.
Pyramidins are cytosine and uracil. Pyrimidines have a single ring structure. There is no thymine in RNA, since it is replaced by an element such as uracil. This is important to understand before paying attention to other structural features of tRNA.
Types of RNA
As you can see, the structure of tRNA cannot be described briefly. One must delve into biochemistry to understand the purpose of the molecule and its true structure. What other ribosomal nucleotides are known? There are also matrix or informational and ribosomal nucleic acids. Abbreviated as mRNA and RRNA. All 3 molecules work closely together in the cell to ensure that the body receives properly structured protein globules.

It is impossible to imagine the work of one polymer without the help of 2 others. The structural features of tRNA become more clear when considered in conjunction with functions that are directly related to the work of ribosomes.
The structure of mRNA, tRNA, and RRNA are similar in many ways. All have ribose at their base. However, their structure and functions are different.
Discovery of nucleic acids
The Swiss Johann Miescher discovered macromolecules in the cell nucleus in 1868, later called nucleins. The name "nuclein" comes from the word (nucleus) - nucleus. Although a little later it was found that in single-celled creatures that do not have a nucleus, these substances are also present. In the middle of the 20th century, he received the Nobel Prize for the discovery of the synthesis of nucleic acids.
in protein synthesis
The name itself - transfer RNA - speaks about the main function of the molecule. This nucleic acid "brings" with it the essential amino acid required by the ribosomal RNA to create a specific protein.
The tRNA molecule has few functions. The first is mRNA codon recognition, the second function is the delivery of building blocks - amino acids for protein synthesis. Some other experts highlight the acceptor function. That is, the addition of amino acids according to the covalent principle. An enzyme such as aminocil-TRNA synthatase helps to “attach” this amino acid.
How is the structure of tRNA related to its functions? This special ribonucleic acid is designed in such a way that on one side there are nitrogenous bases that are always connected in pairs. These are the elements known to us - A, U, C, G. Exactly 3 “letters” or nitrogenous bases make up an anticodon - a reverse set of elements that interacts with the codon according to the principle of complementarity.
This important feature of the tRNA structure ensures that there will be no errors when decoding the template nucleic acid. After all, the exact sequence of amino acids determines whether the protein currently needed by the body is synthesized correctly.
Structural features
What are the structural features of tRNA and its biological role? This is a very ancient structure. Its dimensions are somewhere between 73 and 93 nucleotides. The molecular weight of the substance is 25,000-30,000.
The structure of the secondary structure of tRNA can be analyzed by studying the 5 main elements of the molecule. So, this nucleic acid consists of the following elements:
- loop for contact with enzyme;
- loop for contact with the ribosome;
- anticodon loop;
- acceptor stem;
- the anticodon itself.
And they also isolate a small variable loop in the secondary structure. One arm of all types of tRNA is the same - a stem of two cytosine residues and one adenosine residue. It is at this point that the connection occurs with 1 of the 20 available amino acids. Each amino acid has its own enzyme, its own aminoacyl-tRNA.

All the information that encrypts the structure of everyone is contained in the DNA itself. The structure of TRNA is almost identical in all living beings on the planet. It will look like a leaf when viewed in 2-D.
However, if you take a three-dimensional look, the molecule resembles an L-shaped geometric structure. This is considered the tertiary structure of tRNA. But for ease of study, it is customary to “unwind” it visually. The tertiary structure is formed as a result of the interaction of elements of the secondary structure, those parts that are mutually complementary.
TRNA arms or rings play an important role. One arm, for example, is required for chemical bonding with a particular enzyme.
A characteristic feature of a nucleotide is the presence of a huge number of nucleosides. There are more than 60 types of these minor nucleosides.
TRNA structure and amino acid coding
We know that the tRNA anticodon is 3 molecules long. Each anticodon corresponds to a specific, “personal” amino acid. This amino acid is connected to a tRNA molecule using a special enzyme. As soon as 2 amino acids combine, the bonds with the tRNA are broken. All chemical compounds and enzymes are needed before the required time. This is how the structure and functions of tRNA are interconnected.
In total, there are 61 types of such molecules in the cell. There can be 64 mathematical variations. However, 3 types of tRNA are missing due to the fact that exactly the same number of stop codons in mRNA do not have anticodons.
Interaction of mRNA and tRNA
Let's consider the interaction of the substance with mRNA and RRNA, as well as the structural features of tRNA. The structure and purpose of a macromolecule are interrelated.
The structure of mRNA copies information from a separate section of DNA. DNA itself is too large a compound of molecules, and it never leaves the nucleus. Therefore, we need intermediary RNA—information RNA.

Based on the sequence of molecules that the mRNA has copied, the ribosome builds a protein. A ribosome is a separate polynucleotide structure, the structure of which needs to be clarified.
Ribosomal tRNA: interaction
Ribosomal RNA is a huge organelle. Its molecular weight is 1,000,000 - 1,500,000. Almost 80% of the total amount of RNA is ribosomal nucleotides.

It seems to capture the mRNA chain and wait for anticodons, which will bring tRNA molecules with them. Ribosomal RNA consists of 2 subunits: small and large.
The ribosome is called a “factory” because all the synthesis of substances necessary for everyday life takes place in this organelle. This is also a very ancient cell structure.
How does protein synthesis occur in the ribosome?
The structure of tRNA and its role in protein synthesis are interrelated. The anticodon located on one side of the ribonucleic acid is suitable in shape for its main function - the delivery of amino acids to the ribosome, where the gradual construction of the protein occurs. Essentially, tRNA acts as an intermediary. Its task is only to bring the necessary amino acid.
When information is read from one part of the mRNA, the ribosome moves further along the chain. The matrix is needed only to convey encoded information about the configuration and function of an individual protein. Next, another tRNA with its nitrogenous bases approaches the ribosome. It also decodes the next part of the mRNA.
Decoding occurs as follows. Nitrogenous bases are combined according to the principle of complementarity in the same way as in DNA itself. Accordingly, TRNA sees where it needs to “moor” and to which “hangar” to send the amino acid.

Then, in the ribosome, the amino acids selected in this way are chemically bonded, step by step a new linear macromolecule is formed, which, after completion of synthesis, is twisted into a globule (ball). The used tRNA and mRNA, having completed their function, are removed from the protein “factory”.
When the first part of a codon pairs with an anticodon, a reading frame is determined. Subsequently, if for some reason a frame shift occurs, then some protein feature will be rejected. The ribosome cannot intervene in this process and solve the problem. Only after the process is completed, the 2 RRNA subunits come together again. On average, there is 1 error for every 10 4 amino acids. For every 25 proteins already assembled, there is bound to be at least 1 replication error.
TRNAs as relic molecules
Since tRNA may have existed at the time of the origin of life on earth, it is called a relic molecule. It is believed that RNA is the first structure that existed before DNA and then evolved. RNA world hypothesis - formulated in 1986 by laureate Walter Gilbert. However, this is still difficult to prove. The theory is supported by obvious facts - tRNA molecules are able to store blocks of information and somehow implement this information, that is, perform work.
But opponents of the theory argue that a short period of life of a substance cannot guarantee that tRNA is a good carrier of any biological information. These nucleotides decay quickly. The lifespan of tRNA in human cells ranges from several minutes to several hours. Some types can last up to a day. And if we talk about the same nucleotides in bacteria, then the time frame is much shorter - up to several hours. In addition, the structure and functions of tRNA are too complex for the molecule to become a primary element of the Earth's biosphere.
Transport (soluble) RNA A low molecular weight RNA molecule that performs adapter functions for the specific transfer of amino acids to growing polypeptide chains during translation; tRNAs have a characteristic secondary structure in the form... ...
TRNA. See soluble RNA. (Source: “English-Russian Explanatory Dictionary of Genetic Terms.” Arefiev V.A., Lisovenko L.A., Moscow: Publishing House VNIRO, 1995) ...
tRNA- transport ribonucleic acid transport... Dictionary of abbreviations and abbreviations
Structure of transfer RNA Transfer RNA, tRNA is a ribonucleic acid whose function is to transport amino acids to the site of synthesis ... Wikipedia
Large medical dictionary
See Transport ribonucleic acid... Medical encyclopedia
tRNA nucleotidyl transferase- An enzyme that attaches the CCA triplet to the 3 ends of type II tRNA (i.e., tRNAs whose precursors lack this triplet, some of the tRNAs of prokaryotes and, apparently, all tRNAs of eukaryotes). [Arefyev V.A., Lisovenko L.A. English-Russian explanatory dictionary... ... Technical Translator's Guide
tRNA-like region- * tRNA like segment is a terminal section of the nucleic acid of some RNA containing viruses, capable of aminoacylation and interaction with some specific enzymes. Unlike typical tRNA, tRNA contains... ... Genetics. encyclopedic Dictionary
tRNA-like region- The terminal section of the nucleic acid of some RNA-containing viruses, capable of aminoacylation with an amino acid and interacting with some specific enzymes; unlike tRNA in tRNA p.u. no rare bases found... ... Technical Translator's Guide
TRNA nucleotidyl transferase tRNA nucleotidyl transferase. An enzyme that attaches the CCA triplet to the 3 ends of type II tRNA (i.e., tRNAs whose precursors lack this triplet, some of the tRNAs of prokaryotes and, apparently, all tRNAs of eukaryotes).... ... Molecular biology and genetics. Dictionary.
Books
- Physics of hidden parameters: , I. Bogdanov. The work eliminates the contradictions that prevent the recognition of the physics of hidden parameters, created on the basis of the theory of electric fields of rotation. A proof of Bohr's postulates has been found...
Textbook. Despite the fact that tRNA is much smaller, the story about its structure, features and functioning deserves a separate chapter.
So, tRNA is an “adapter” that at one end recognizes the three-letter sequence of the genetic code, matching it with the only corresponding amino acid attached to the other end of the tRNA. At the end of the transfer RNA touching the messenger RNA there are 3 nucleotides that form anticodon. Only if the anticodon is complementary to the mRNA region can the transfer RNA attach to it. But even in this case, tRNA cannot join mRNA on its own; it needs the help of the ribosome, which is the site of their interaction, as well as an active participant in translation. For example, it is the ribosome that creates bonds between amino acids brought by tRNA, forming a protein chain.
The structural features of tRNA are determined by the genetic code, that is, the rules for constructing a protein according to a gene, which transfer RNA reads. This code works in every creature living on Earth: the creation of a virus is written in the same three-letter codons that are used to write the “assembly instructions” of a dolphin. It has been experimentally verified that the genes of one living creature, placed in the cell of another, are perfectly copied and translated into proteins that are indistinguishable from the genes reproduced in the host cells. The uniformity of the genetic code is the basis for the production of insulin and many other human enzymes by colonies of modified Escherichia coli, which are used as medicines for people whose bodies are unable to produce them, or produce them insufficiently. Despite the obvious differences between humans and E. coli, human proteins are easily created from his designs using the E. coli duplicating machine. It is not surprising that transfer RNAs of different creatures differ very little.

Every codon on this list except three stop codons, giving a signal about the completion of translation, must be recognized by the transfer RNA. Recognition is accomplished by attaching an anticodon to the messenger RNA, which can only bind to one codon from the list, so tRNA can only recognize one codon. This means that there are at least 61 types of these molecules in the cell. In fact, there are even more of them, since in some situations, in order to read messenger RNA, it is not enough just to have the desired anticodon: other conditions must be met, in accordance with which a special, modified tRNA is created.
At first glance, such a variety of tRNAs should significantly complicate the translation process: after all, each of these molecules will check the messenger RNA codon substituted for it by the ribosome for compliance with its anticodon - it would seem that there is so much meaningless mechanical work, so much wasted time and energy. But as a result of evolution, cellular mechanisms have also evolved to prevent this problem. For example, the amount of tRNA of each type in a cell corresponds to how often the amino acid carried by that type is found in the proteins being built. There are amino acids that are rarely used by the cell, and there are those that are often used, and if the number of tRNAs carrying them were the same, this would significantly complicate the assembly of proteins. Therefore, there are few “rare” amino acids and their corresponding tRNAs in the cell, while frequently occurring ones are produced in large quantities.

With such a variety of tRNA molecules, they are all very similar, so when considering their structure and functions, we will mainly study the features common to all species. When you look at the three-dimensional diagram of tRNA, it looks like a dense jumble of atoms. It seems incredible that this complex molecule is produced by folding a long chain of nucleotides, but that is exactly how it is formed.
You can trace the stages of its formation, starting with the very first: the compilation of a nucleotide sequence by RNA polymerase in accordance with the gene containing information about this transfer RNA. The order in which these nucleotides appear one after another and their number is called tRNA primary structure. It turns out that it is the primary structure of tRNA that is encoded in the gene read by RNA polymerase. In general, the primary structure is a sequence of relatively simple molecules of one type, from which a more complex, folded polymer molecule is composed. For example, the primary structure of a protein molecule is the simple sequence of its constituent amino acids.

Any chain of nucleotides cannot be in an unfolded state in a cell, simply stretched out in a line. At the edges of the nucleotides there are too many positively and negatively charged parts that easily form hydrogen bonds with each other. How the same bonds are formed between the nucleotides of two DNA molecules, connecting them into a double helix, is described in, and for details about hydrogen bonds you can go to. Hydrogen bonds are less strong than the bonds between atoms in molecules, but they are enough to twist the tRNA strand in an intricate way and keep it in that position. At first, these bonds form only between some nucleotides, folding the tRNA into a shape like a clover leaf. The result of this initial folding is called secondary structure tRNA. The diagram on the left shows that only some nucleotides are connected by hydrogen bonds, while others remain unpaired, forming rings and loops. Differences between the secondary structure of different tRNA species are due to differences in their primary structure. This manifests itself in different lengths of the “clover leaves” or “stems” due to the different lengths of the initial chain of nucleotides.
Another difference in the primary structure of different tRNAs is that only in some positions they have the same nucleotides (in the diagram above they are marked with the first letters of their names), but most of the nucleotides in different tRNAs differ from each other. The above diagram is common to all tRNAs, so the different nucleotides are marked with numbers.
The main functional parts of tRNA are:
=) anticodon, that is, a nucleotide sequence complementary to the only codon of the messenger RNA, located on anticodon hairpin
=) acceptor end, to which an amino acid can be attached. It is located on the opposite side of the anticodon hairpin.
In reality, not a single tRNA looks like it does in the secondary structure diagram, because only some nucleotides joined together to form it, while the rest remained unpaired. Due to the formation of hydrogen bonds between nucleotides from different parts of the clover leaf, it folds further into a much more complex tertiary structure in the shape of the letter L. You can understand exactly how the different parts of the secondary structure bent to form the tertiary structure by matching the colors in their diagrams below. The anticodon hairpin, indicated in blue and gray, remains at the bottom (it is worth remembering that this “down” is arbitrary: it is convenient to depict tRNA in this spatial orientation in protein translation diagrams), and the acceptor end (yellow) is bent to the side.

This is what tRNA looks like when it is ready to attach an amino acid. tRNA is not capable of combining with an amino acid on its own; this requires the participation of a special enzyme: aminoacyl-tRNA synthetases. The number of types of synthetases in a cell coincides with the number of types of tRNA.
The uniformity of the shape of all types of tRNA is necessary so that the ribosome can recognize any of them, facilitate their docking with mRNA, and move them within itself from one site to another. If different types of tRNA were significantly different from each other, this would make the work of the ribosome extremely difficult, critically reducing the rate of protein synthesis. Natural selection thus aims to make tRNAs similar to each other. But at the same time, there is another factor that requires the existence of noticeable differences between different types of tRNA: after all, it is necessary to recognize each type and attach to it the only amino acid corresponding to it. Obviously, these differences should be noticeable, but not too significant, so the work of recognizing tRNA types turns into a jewelry process. And this is exactly what aminoacyl-tRNA synthetases do: each of them can contact only one of the 20 amino acids and attach it to exactly those types of tRNA that correspond to this amino acid. From the table with the genetic code it is clear that each amino acid is encoded by several nucleotide sequences, therefore, for example, all four tRNAs with anticodons CGA, CGG, CGU and CGC will be recognized by the same synthetase, which attaches alanine to them. Such tRNAs processed by one synthetase are called related.
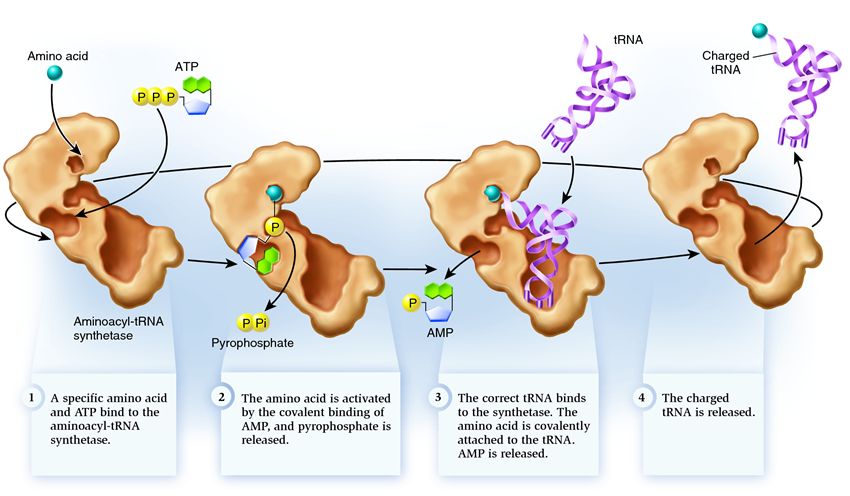
Synthetase belongs to a group of enzymes whose function is to bind to separately existing molecules and combine them into one:
1 . synthetase connects an amino acid and an ATP molecule. Two phosphate groups break away from ATP, releasing the energy needed for the next steps. The adenosine monophosphate (AMP) remaining from the destroyed molecule attaches to the amino acid, preparing it for connection with the acceptor hairpin.
2 . the synthetase attaches to itself one of the related tRNAs corresponding to this amino acid.

At this stage, the correspondence of the transfer RNA synthetase is checked. There are several recognition methods, and each synthetase has a unique combination of them. At least one nucleotide of the anticodon is involved in the interaction of the synthetase and tRNA. The acceptor hairpin also requires checking: the presence of specific nucleotides on it that are common to related tRNAs corresponding to the desired amino acid is determined. Nucleotides from other parts of tRNA can also participate in matching by binding to specific sites in the synthetase. An incorrect tRNA may coincide with the desired one in some parameters, but due to an incomplete match, it will attach to the synthetase slowly and loosely, easily falling off. And the correct tRNA will stick to the synthetase quickly and tightly, as a result of which the structure of the synthetase changes, starting the process aminoacylation , that is, the addition of an amino acid to tRNA.

3 . aminoacylation involves replacing an AMP molecule attached to an amino acid with a tRNA molecule. After this replacement, AMP leaves the synthetase and tRNA is held back for one final check of the amino acid. If the attached amino acid is detected as incorrect, it will be detached from the tRNA, leaving the amino acid's place in the synthetase empty, and another molecule can join there. The new amino acid will go through the stages of combining with ATP and tRNA, and will also be tested. If no mistakes were made, the tRNA charged with the amino acid is released: it is ready to play its role in protein translation. And the synthetase is ready to attach new amino acids and tRNAs, and the cycle begins again.
Much depends on the correct functioning of the aminoacyl-tRNA synthetase: if a failure occurs at this stage, the wrong amino acid will be attached to the tRNA. And it will be built into the protein growing on the ribosome, because tRNA and the ribosome do not have the function of checking the correspondence of the codon and the amino acid. The consequences of an error can be minor or catastrophic, and in the course of natural selection, creatures with enzymes that do not have the function of such checks were replaced by more adaptable ones that had different options for establishing the correspondence between amino acid and tRNA. Therefore, in modern cells, the synthetase combines with the wrong amino acid on average in one case out of 50 thousand, and with the wrong tRNA only once in 100 thousand connections.

Some amino acids differ from each other by only a few atoms. If you look at their diagrams, it becomes obvious that the likelihood of confusing arginine with alanine is much less likely than mistaking isoleucine for leucine or valine. Therefore, each synthetase that binds to one of the amino acids that are similar to each other has additional verification mechanisms. Here is an example of such an adaptation in isoleucine-tRNA synthetase:

Each synthetase has synthetic center, in which an amino acid is added to tRNA. The acceptor hairpin of the tRNA captured by the synthetase ends up there, as does the amino acid, ready to react with it. The work of some synthetases ends immediately after the amino acid and tRNA are combined. But Ile-tRNA synthetase has an increased probability of making errors due to the existence of other amino acids similar to isoleucine. Therefore she also has correctional center: From the name it is clear what role it plays in the process of connecting tRNA and amino acid. The figure on the right shows that the position of the end of the acceptor tRNA hairpin in the synthetic center of Ile-tRNA synthetase gives this hairpin an unnatural bend. However, the synthetase holds the tRNA in this position until an amino acid is added to it. After this connection has occurred, the need for the acceptor hairpin to be located in the synthetic center is exhausted, and the tRNA straightens, ending up with its end with the amino acid attached to it in the correction center.

Of course, the synthetic center also plays a role in screening out amino acids that are not suitable for the synthetase. To get into it, a molecule must meet a number of conditions, including having the right size. Although leucine and isoleucine contain the same number of atoms, due to differences in spatial structure, leucine is larger. Therefore, it cannot penetrate the synthetic center, the size of which corresponds to the more compact isoleucine, and simply bounces off Ile-tRNA synthetase.
But valine, which is the smallest of these three molecules with a similar atomic structure, easily takes the place of isoleucine in the synthetic center, and the synthetase attaches it to tRNA. This is where the synthetase correction center comes into play. If the straightening acceptor hairpin is correctly charged and carries isoleucine, then it cannot squeeze inside the correction center: it is simply too small for this molecule. Thus, nothing holds the straightened tRNA anymore, and it is disconnected from the synthetase. But if valine is attached to the tRNA, it slips into the correction center, thereby holding the tRNA connected to it in the synthetase. Such an excessively long presence of tRNA inside is an error signal for the synthetase, changing its spatial configuration. As a result:
=) valine is uncoupled from tRNA and removed from the synthetase
=) the acceptor hairpin returns to the synthetic center, awaiting attachment to the amino acid
=) the synthetase binds to the new amino acid, “charges” the tRNA with it and again checks whether isoleucine was used for this.
A similar dual recognition mechanism is used by other synthetases.
Aminoacyl-tRNA synthetase (ARCase) is a synthetase enzyme that catalyzes the formation of aminoacyl-tRNA in the esterification reaction of a certain amino acid with its corresponding tRNA molecule. Each amino acid has its own aminoacyl-tRNA synthetase. ARSases ensure compliance with the nucleotide triplets of the genetic code (tRNA anticodon) of amino acids built into the protein, and thus ensure the correctness of the subsequent reading of genetic information from mRNA during protein synthesis on ribosomes. Most APCases consist of 1, 2 or 4 identical polypeptide chains. The molecular weight of polypeptide chains is 30-140 thousand. Many APCases contain two active centers. There are 3 plots. The first region does not have specificity; it is the same for all enzymes; it is the site of ATP attachment. The second region has strict specificity; a certain AK is attached here, which is why it is called ARSase; for example, if it attaches methionine, it is called methionyl-tRNA synthetase. The third region is also a strictly specific region and can only bind to a specific tRNA. Thus, the enzyme is necessary for amino acid and tRNA recognition.
The specificity of reactions catalyzed by APCases is very high, which determines the accuracy of protein synthesis in a living cell. If A. carries out an erroneous aminoacylation of a tRNA with an amino acid similar in structure, a correction will occur through the hydrolysis of erroneous AA-tRNAs catalyzed by the same APCase to AA and tRNA. The cytoplasm contains a full set of APCases; chloroplasts and mitochondria have their own APCases.
Transfer RNA. Structure, functions. The structure of ribosomes.
All tRNAs have common features both in their primary structure and in the way the polynucleotide chain is folded into a secondary structure due to interactions between the bases of nucleotide residues.
Primary structure of tRNA
tRNAs are relatively small molecules, the length of their chains varies from 74 to 95 nucleotide residues. All tRNAs have the same 3" end, built from two cytosine residues and one adenosine residue (CCA end). It is the 3" terminal adenosine that binds to the amino acid residue during the formation of aminoacyl-tRNA. The CCA end is attached to many tRNAs by a special enzyme. The nucleotide triplet complementary to the codon for an amino acid (anticodon) is located approximately in the middle of the tRNA chain. At certain positions in the sequence, almost all types of tRNA contain the same (conserved) nucleotide residues. Some positions may contain either only purine or only pyrimidine bases (they are called semiconservative residues).
All tRNA molecules are characterized by the presence of a large number (up to 25% of all residues) of various modified nucleosides, often called minor. They are formed at various places in molecules, in many cases well-defined, as a result of modification of ordinary nucleoside residues by special enzymes.
Secondary structure of tRNA
folding of the chain into a secondary structure occurs due to the mutual complementarity of the chain sections. The three chain fragments become complementary when folded onto themselves, forming hairpin-like structures. In addition, the 5" end is complementary to the region close to the 3" end of the chain, with their antiparallel arrangement; they form the so-called acceptor stem. The result is a structure characterized by the presence of four stems and three loops, which is called the “clover leaf”. The stem and loop form a branch. At the bottom is the anticodon branch, which contains an anticodon triplet as part of its loop. To the left and right of this are the D and T branches, respectively named for the presence of the unusual conserved nucleosides dihydrouridine (D) and thymidine (T) in their loops. The nucleotide sequences of all tRNAs studied can be folded into similar structures. In addition to the three cloverleaf loops, tRNA also has an additional, or variable, loop (V-loop). Its sizes vary sharply among different tRNAs, varying from 4 to 21 nucleotides, and according to the latest data, up to 24 nucleotides.
Spatial (tertiary) structure of tRNA
Due to the interaction of elements of the secondary structure, a tertiary structure is formed, which is called the L-form due to its resemblance to the Latin letter L (Fig. 2 and 3). By base stacking, the acceptor stem and the cloverleaf T stem form one continuous double helix, and the other two stems, the anticodon and D, form another continuous double helix. In this case, the D- and T-loops are brought closer together and are fastened together by the formation of additional, often unusual, base pairs. Conservative or semi-conservative residues, as a rule, take part in the formation of these pairs. Similar tertiary interactions hold together some other parts of the L-structure
The main purpose of transfer RNA (tRNA) is to deliver activated amino acid residues to the ribosome and ensure their inclusion in the synthesized protein chain in accordance with the program written by the genetic code in the matrix, or information, RNA (mRNA).
The structure of ribosomes.
Ribosomes are ribonucleoprotein formations - a kind of “factory” in which amino acids are assembled into proteins. Eukaryotic ribosomes have a sedimentation constant of 80S and consist of 40S (small) and 60S (large) subunits. Each subunit includes rRNA and proteins.
Proteins are part of the ribosomal subunits in one copy and perform a structural function, providing interaction between mRNA and tRNA associated with an amino acid or peptide.
In the presence of mRNA, the 40S and 60S subunits combine to form a complete ribosome, which weighs approximately 650 times the mass of a hemoglobin molecule.
Apparently, rRNA determines the basic structural and functional properties of ribosomes, in particular, ensures the integrity of ribosomal subunits, determines their shape and a number of structural features.
The union of the large and small subunits occurs in the presence of messenger RNA (mRNA). One molecule of mRNA usually links several ribosomes together like a string of beads. This structure is called a polysome. Polysomes are freely located in the main substance of the cytoplasm or attached to the membranes of the rough cytoplasmic reticulum. In both cases, they serve as a site of active protein synthesis.
Like the endoplasmic reticulum, ribosomes were only discovered using an electron microscope. Ribosomes are the smallest of cellular organelles.
The ribosome has 2 centers for the attachment of tRNA molecules: aminoacyl (A) and peptidyl (P) centers, in the formation of which both subunits participate. Together, centers A and P include a region of mRNA equal to 2 codons. During translation, center A binds aa-tRNA, the structure of which is determined by the codon located in the region of this center. The structure of this codon encodes the nature of the amino acid that will be included in the growing polypeptide chain. The P center is occupied by peptidyl-tRNA, i.e. tRNA linked to a peptide chain that has already been synthesized.
In eukaryotes, there are two types of ribosomes: “free”, found in the cytoplasm of cells, and those associated with the endoplasmic reticulum (ER). Ribosomes associated with the ER are responsible for the synthesis of proteins “for export”, which are released into the blood plasma and are involved in the renewal of ER proteins, the Golgi apparatus membrane, mitochondria or lysosomes
Synthesis of a polypeptide molecule. Initiation and elongation.
Protein synthesis is a cyclic, multi-step, energy-dependent process in which free amino acids are polymerized into a genetically determined sequence to form polypeptides.
The second stage of matrix protein synthesis, the actual translation that occurs in the ribosome, is conventionally divided into three stages: initiation, elongation and termination.
Initiation.
A sequence of DNA transcribed into a single mRNA, starting with a lookup at the 5' end and ending with a terminator at the 3' end, is a unit of transcription and corresponds to the concept of a “gene”. Control of gene expression can be carried out at the translation initiation stage. At this stage, RNA polymerase recognizes the promoter - a fragment 41-44 bp long. Transcription occurs in the 5`-3` direction or from left to right. Sequences lying to the right of the starting nucleotide, from which tRNA synthesis begins, are designated by numbers with a + sign (+1,+2..) and those to the left with a – (-1,-2) sign. Thus, the region of DNA to which DNA polymerase attaches occupies a region with coordinates from approximately -20 to +20. All promoters contain the same nucleotide sequences, called conserved. Such sequences serve as signals recognized by RNA polymerases. The starting point is usually purine. Immediately to the left of this is 6-9 bp known as the Pribnow sequence (or box): TATAAT. It can vary somewhat, but the first two bases are inserted into most promoters. It is assumed that since it is formed by a region rich in AT pairs, connected by two hydrogen bonds, the DNA in this place is more easily separated into individual strands. This creates conditions for the functioning of RNA polymerase. Along with this, the Pribnow box is necessary for orientation in such a way that mRNA synthesis proceeds from left to right, i.e. from 5`-3`. The center of Pribnow's box is at nucleotide -10. A sequence of similar composition is located in another region centered at position 35. This region, consisting of 9 bp, is designated sequence 35 or the recognition region. It is the site to which the factor binds, thereby determining the efficiency with which RNA polymerase cannot begin transcription without special proteins. One of them is the CAP or CRP factor.
In eukaryotes, promoters that interact with RNA polymerase II have been studied in more detail. They contain three homologous sections in areas with coordinates at points -25, -27 and also at the starting point. The starting bases are adenine, flanked on both sides by pyrimidines. At a distance of 19-25 bp. 7 bp are located to the left of the site. TATAA, known as the TATA sequence, or Hogness box, is often surrounded by regions rich in GC pairs. Even further to the left, at positions -70 to -80, is the GTZ or CAATCT sequence, called the CAAT box. It is assumed that the TATA sequence controls the choice of the starting nucleotide, and CAAT controls the primary binding of RNA polymerase to the DNA template.
Elongation. The mRNA elongation stage is similar to DNA elongation. It requires ribonucleotide triphosphates as precursors. The stage of transcription elongation, that is, the growth of the mRNA chain, occurs by attaching ribonucleotide monophosphates to the 3'-end of the chain with the release of pyrophosphate. Copying in eukaryotes usually occurs on a limited section of DNA (gene), although in prokaryotes, in some cases, transcription can occur sequentially through several linked genes that form a single operon and one common promoter. In this case, polycistronic mRNA is formed.
Regulation of gene activity using the example of the lactose operon.
The lactose operon is a polycistronic operon of bacteria that encodes genes for lactose metabolism.
Regulation of the expression of lactose metabolism genes in Escherichia coli was first described in 1961 by scientists F. Jacob and J. Monod. A bacterial cell synthesizes enzymes involved in lactose metabolism only when lactose is present in the environment and the cell lacks glucose.
The lactose operon consists of three structural genes, a promoter, an operator and a terminator. It is assumed that the operon also includes a regulator gene that encodes a repressor protein.
Structural genes of the lactose operon - lacZ, lacY and lacA:
lacZ encodes the enzyme β-galactosidase, which breaks down the disaccharide lactose into glucose and galactose,
lacY encodes β-galactoside permease, a membrane transport protein that transports lactose into the cell.
lacA encodes β-galactoside transacetylase, an enzyme that transfers an acetyl group from acetyl-CoA to beta-galactosides.
At the beginning of each operon there is a special gene - the operator gene. One m-RNA is usually formed on the structural genes of one operon, and these genes can be simultaneously active or inactive. As a rule, structural genes in an operon are in a state of repression.
A promoter is a section of DNA recognized by the enzyme RNA polymerase, which ensures the synthesis of m-RNA in the operon, preceded by a section of DNA to which the Sar protein, an activator protein, is attached. These two sections of DNA consist of 85 nucleotide pairs. After the promoter, the operon contains an operator gene, consisting of 21 nucleotide pairs. A repressor protein produced by the regulator gene is usually associated with it. Behind the operator gene there is a spacer (space). Spacers are non-informative sections of a DNA molecule of various lengths (sometimes up to 20,000 base pairs), which apparently take part in regulating the transcription process of a neighboring gene.
The operon ends with a terminator - a small section of DNA that serves as a stop signal for m-RNA synthesis on this operon.
Acceptor genes serve as attachment sites for various proteins that regulate the functioning of structural genes. If lactose, penetrating into the cell (in this case it is called an inducer), blocks proteins encoded by the regulator gene, then they lose the ability to attach to the operator gene. The operator gene goes into an active state and turns on structural genes.
RNA polymerase, with the help of the Cap protein (activator protein), attaches to the promoter and, moving along the operon, synthesizes pro-m-RNA. During transcription, m-RNA reads genetic information from all structural genes in one operon. During translation on the ribosome, several different polypeptide chains are synthesized in accordance with the codons contained in m-RNA - nucleotide sequences that ensure the initiation and termination of translation of each chain. The type of regulation of gene function, considered using the example of the lactose operon, is called negative induction of protein synthesis.
Regulation of gene activity using the example of the tryptophan operon.
Another type of gene regulation is negative repression, studied in E.coU using the example of the operon that controls the synthesis of the amino acid tryptophone. This operon consists of 6700 nucleotide pairs and contains 5 structural genes, an operator gene and two promoters. The regulator gene ensures constant synthesis of a regulatory protein that does not affect the functioning of the trp operon. When there is an excess of tryptophan in the cell, the latter binds to the regulatory protein and changes it in such a way that it binds to the operone and represses the synthesis of the corresponding m-RNA.
Negative and positive control of genetic activity.
The so-called positive induction is also known, when the protein product of the regulator gene activates the operation of the operon, i.e. is not a repressor, but an activator. This division is conditional, and the structure of the acceptor part of the operon and the action of the gene regulator in prokaryotes are very diverse.
The number of structural genes in an operon in prokaryotes ranges from one to twelve; An operon may have either one or two promoters and terminators. All structural genes localized in one operon, as a rule, control a system of enzymes that provide one chain of biochemical reactions. There is no doubt that in the cell there are systems that coordinate the regulation of several operons.
Proteins that activate the synthesis of m-RNA are attached to the first part of the gene acceptor - the operator, and to the end of it - repressor proteins that suppress the synthesis of m-RNA. A single gene is regulated by one of several proteins, each of which attaches to a corresponding acceptor site. Different genes can have common regulators and identical operator regions. Gene regulators do not act simultaneously. First, one immediately turns on one group of genes, then after a while the other turns on another group, i.e. regulation of gene activity occurs in “cascades”, and a protein synthesized at one stage can be a regulator of protein synthesis at the next stage.
The structure of chromosomes. Karyotype. Idiogram. Models of chromosome structure.
Eukaryotic chromosomes have a complex structure. The basis of the chromosome is a linear (not closed in a ring) macromolecule of deoxyribonucleic acid (DNA) of considerable length (for example, in the DNA molecules of human chromosomes there are from 50 to 245 million pairs of nitrogenous bases). When stretched, the length of a human chromosome can reach 5 cm. In addition to it, the chromosome includes five specialized proteins - H1, H2A, H2B, H3 and H4 (the so-called histones) and a number of non-histone proteins. The amino acid sequence of histones is highly conserved and practically does not differ in the most diverse groups of organisms. In interphase, chromatin is not condensed, but even at this time its threads are a complex of DNA and proteins. Chromatin is a deoxyribonucleoprotein, visible under a light microscope in the form of thin threads and granules. The DNA macromolecule wraps around the octomers (structures consisting of eight protein globules) of the histone proteins H2A, H2B, H3 and H4, forming structures called nucleosomes.
In general, the whole structure is somewhat reminiscent of beads. A sequence of such nucleosomes connected by the H1 protein is called a nucleofilament, or nucleosomal thread, with a diameter of about 10 nm.
The condensed chromosome has the shape of an X (often with unequal arms) because the two chromatids resulting from replication are still connected at the centromere. Each cell of the human body contains exactly 46 chromosomes. Chromosomes are always paired. There are always 2 chromosomes of each type in a cell; pairs differ from each other in length, shape and the presence of thickenings or constrictions.
A centromere is a specially organized region of a chromosome that is common to both sister chromatids. The centromere divides the chromosome body into two arms. Depending on the location of the primary constriction, the following types of chromosomes are distinguished: equal-armed (metacentric), when the centromere is located in the middle and the arms are approximately equal in length; unequal arms (submetacentric), when the centromere is displaced from the middle of the chromosome, and the arms are of unequal length; rod-shaped (acrocentric), when the centromere is shifted to one end of the chromosome and one arm is very short. Some chromosomes may have secondary constrictions that separate a region called a satellite from the chromosome body.
The study of the chemical organization of chromosomes in eukaryotic cells has shown that they consist mainly of DNA and proteins. As has been proven by numerous studies, DNA is a material carrier of the properties of heredity and variability and contains biological information - a program for the development of a cell or organism, recorded using a special code. Proteins make up a significant part of the substance of chromosomes (about 65% of the mass of these structures). The chromosome as a complex of genes is an evolutionarily established structure characteristic of all individuals of a given species. The relative position of genes within a chromosome plays an important role in the nature of their functioning.
A graphic representation of a karyotype showing its structural features is called an idiogram.
A set of chromosomes specific to a certain species in number and structure is called a karyotype.
Histones.
Nucleosome structure.
Histones are a major class of nucleoproteins, nuclear proteins required for the assembly and packaging of DNA strands into chromosomes. There are five different types of histones, named H1/H5, H2A, H2B, H3, H4. The sequence of amino acids in these proteins practically does not differ in organisms of different levels of organization. Histones are small, highly basic proteins that bind directly to DNA. Histones take part in the structural organization of chromatin, neutralizing negatively charged phosphate groups of DNA due to the positive charges of amino acid residues, which makes possible the dense packaging of DNA in the nucleus.
Two molecules each of histones H2A, H2B, H3, and H4 form an octamer wrapped around a 146-bp segment of DNA that forms 1.8 turns of a helix on top of the protein structure. This 7 nm diameter particle is called a nucleosome. A section of DNA (linker DNA) that is not directly in contact with the histone octamer interacts with histone H1.
The group of non-histone proteins is highly heterogeneous and includes structural nuclear proteins, many enzymes and transcription factors associated with certain sections of DNA and regulating gene expression and other processes.
Nucleosome is a chromatin subunit consisting of DNA and a set of four pairs of histone proteins H2A, H2B, H3 and H4 of one histone H1 molecule. Histone H1 binds to linker DNA between two nucleosomes.
The nucleosome is the elementary packaging unit of chromatin. It consists of a DNA double helix wrapped around a specific complex of eight nucleosomal histones (histone octamer). The nucleosome is a disc-shaped particle with a diameter of about 11 nm, containing two copies of each of the nucleosomal histones (H2A, H2B, H3, H4). The histone octamer forms a protein core around which double-stranded DNA is wrapped twice (146 DNA base pairs per histone octamer).
The nucleosomes that make up the fibrils are located more or less evenly along the DNA molecule at a distance of 10-20 nm from each other.
Levels of chromosome packaging in eukaryotes. Chromatin condensation.
Thus, the levels of DNA packaging are as follows:
1) Nucleosomal (2.5 turns of double-stranded DNA around eight molecules of histone proteins).
2) Supernucleosomal - chromatin helix (chromonema).
3) Chromatid - spiralized chromonema.
4) Chromosome - the fourth degree of DNA sperialization.
In the interphase nucleus, chromosomes are decondensed and represented by chromatin. The uncoiled area containing genes is called euchromatin (loose, fibrous chromatin). This is a prerequisite for transcription. During dormancy between divisions, certain chromosome regions and entire chromosomes remain compact.
These coiled, highly stained areas are called heterochromatin. They are transcriptionally inactive. There are facultative and constitutive heterochromatin.
Facultative heterochromatin is informative because contains genes and can be converted into euchromatin. Of two homologous chromosomes, one may be heterochromatic. Constitutive heterochromatin is always heterochromatic, non-formative (does not contain genes) and therefore is always inactive regarding transcription.
Chromosomal DNA consists of more than 108 base pairs, from which informative blocks are formed - genes arranged linearly. They account for up to 25% of DNA. A gene is a functional unit of DNA containing information for the synthesis of polypeptides, or all RNA. Between genes there are spacers - non-informative DNA segments of different lengths. Redundant genes are represented by a large number - 104 identical copies. Examples are genes for t-RNA, r-RNA, and histones. Sequences of the same nucleotides occur in DNA. They can be moderately repetitive or highly repetitive sequences. Moderately repetitive sequences reach 300 nucleotide pairs with repetitions of 102 - 104 and most often represent spacers, redundant genes.
Highly repetitive sequences (105 - 106) form constitutive heterochromatin. About 75% of all chromatin is not involved in transcription; it consists of highly repetitive sequences and non-transcribed spacers.
Preparation of chromosome preparations. Use of colchicine. Hypotony, fixation and staining.
Depending on the degree of proliferative activity of cells of different tissues in vivo and in vitro, direct and indirect methods for obtaining chromosome preparations are distinguished.
1) Direct methods are used in the study of tissues with high mitotic activity (bone marrow, chorion and placenta, lymph node cells, embryonic tissue at an early stage of development). Chromosome preparations are prepared directly from freshly obtained material after special processing.
2) Indirect methods include obtaining chromosome preparations from any tissue after its preliminary cultivation for various periods of time.
There are many modifications of direct and indirect methods for preparing chromosome preparations, but the main stages of obtaining metaphase plates remain unchanged:
1. The use of colchicine (colcemid) - an inhibitor of the formation of the mitotic spindle, which stops cell division at the metaphase stage.
2. Hypotonic shock using solutions of potassium or sodium salts, which, due to the difference in osmotic pressure inside and outside the cells, cause them to swell and break interchromosomal bonds. This procedure leads to the separation of chromosomes from each other, contributing to their greater scattering in the metaphase plates.
3. Fixation of cells using glacial acetic acid and ethanol (methanol) in a ratio of 3:1 (Carnoy's fixative), which helps preserve the chromosome structure.
4. Dropping the cell suspension onto glass slides.
5. Staining of chromosome preparations.
A number of staining (banding) methods have been developed to reveal a complex of transverse marks (stripes, bands) on a chromosome. Each chromosome is characterized by a specific complex of bands. Homologous chromosomes are stained identically, with the exception of polymorphic regions where different allelic variants of genes are localized. Allelic polymorphism is characteristic of many genes and occurs in most populations. Detection of polymorphisms at the cytogenetic level has no diagnostic value.
A. Q-staining. The first method of differential staining of chromosomes was developed by the Swedish cytologist Kaspersson, who used the fluorescent dye quinine mustard for this purpose. Under a fluorescence microscope, areas with unequal fluorescence intensity are visible on the chromosomes - Q-segments. The method is best suited for the study of Y chromosomes and is therefore used to quickly determine genetic sex, detect translocations (exchanges of regions) between the X and Y chromosomes or between the Y chromosome and autosomes, and also for viewing a large number of cells when it is necessary to find out whether a patient with sex chromosome mosaicism has a clone of cells bearing the Y chromosome.
B. G-staining. After extensive pretreatment, often using trypsin, the chromosomes are stained with Giemsa stain. Under a light microscope, light and dark stripes are visible on the chromosomes - G-segments. Although the location of the Q segments corresponds to the location of the G segments, G staining has proven to be more sensitive and has taken the place of Q staining as the standard method for cytogenetic analysis. G-staining is best for detecting small aberrations and marker chromosomes (segmented differently from normal homologous chromosomes).
B. R-staining gives a picture opposite to G-staining. Giemsa stain or acridine orange fluorescent dye is usually used. This method reveals differences in the staining of homologous G- or Q-negative regions of sister chromatids or homologous chromosomes.
G. C-staining is used to analyze the centromeric regions of chromosomes (these regions contain constitutive heterochromatin) and the variable, brightly fluorescent distal part of the Y chromosome.
E. T-staining is used to analyze the telomeric regions of chromosomes. This technique, as well as staining of nucleolar organizer regions with silver nitrate (AgNOR staining), is used to clarify the results obtained by standard chromosome staining.
The synthesis of rRNA and tRNA precursors is similar to the synthesis of ire-mRNA. The primary transcript of ribosomal RNA does not contain introns, and under the action of specific RNases it is cleaved to form 28S-, 18S- and 5.8S-rRNA; 5S-pRNA is synthesized with the participation of RNA polymerase III.
rRNA and tRNA.
Primary tRNA transcripts are also converted to mature forms by partial hydrolysis.
All types of RNA are involved in protein biosynthesis, but their functions in this process are different. The role of the matrix that determines the primary structure of proteins is performed by messenger RNA (mRNA). The use of cell-free protein biosynthesis systems is important for studying translation mechanisms. If tissue homogenates are incubated with a mixture of amino acids, at least one of which is labeled, then protein biosynthesis can be detected by the inclusion of the label in proteins. The primary structure of the protein being synthesized is determined by the primary structure of the mRNA added to the system. If the cell-free system is composed of globin mRNA (it can be isolated from reticulocytes), globin (a- and 3-globin chains) is synthesized; if albumin is synthesized with albumin mRNA isolated from hepatocytes, etc.
14. Replication meaning:
a) the process is an important molecular mechanism that underlies all types of cell division in proeukaryotes, b) ensures all types of reproduction of both unicellular and multicellular organisms,
c) maintains the constancy of cellular
composition of organs, tissues and the body as a result of physiological regeneration
d) ensures the long-term existence of certain individuals;
e) ensures the long-term existence of species of organisms;
f) the process promotes accurate doubling of information;
g) errors (mutations) are possible during the replication process, which can lead to disturbances in protein synthesis with the development of pathological changes.
The unique property of a DNA molecule to duplicate itself before cell division is called replication.
Special properties of native DNA as a carrier of hereditary information:
1) replication - the formation of new chains is complementary;
2) self-correction - DNA polymerase cleaves off erroneously replicated sections (10-6);
3) reparation - restoration;
These processes occur in the cell with the participation of special enzymes.
How the repair system works Experiments that made it possible to identify the mechanisms of restoration and the very existence of this ability were carried out using single-celled organisms. But repair processes are inherent in living cells of animals and humans. Some people suffer from xeroderma pigmentosum. This disease is caused by a lack of cells' ability to resynthesize damaged DNA. Xeroderma is inherited. What does the reparation system consist of? The four enzymes that support the repair process are DNA helicase, -exonuclease, -polymerase and -ligase. The first of these compounds is able to recognize damage in the chain of the deoxyribonucleic acid molecule. It not only recognizes, but also cuts the chain in the right place to remove the modified segment of the molecule. The elimination itself is carried out using DNA exonuclease. Next, a new section of the deoxyribonucleic acid molecule is synthesized from amino acids in order to completely replace the damaged section. Well, the final chord of this most complex biological procedure is performed using the enzyme DNA ligase. It is responsible for attaching the synthesized site to the damaged molecule. Once all four enzymes have done their job, the DNA molecule is completely renewed and all damage is a thing of the past. This is how the mechanisms inside a living cell work harmoniously.
Classification At the moment, scientists distinguish the following types of reparation systems. They are activated depending on various factors. These include: Reactivation. Recombination restoration. Heteroduplex repair. Excision repair. Reunion of non-homologous ends of DNA molecules. All single-celled organisms have at least three enzyme systems. Each of them has the ability to carry out the recovery process. These systems include: direct, excision and post-replicative. Prokaryotes possess these three types of DNA repair. As for eukaryotes, they have at their disposal additional mechanisms called Miss-mathe and Sos-repair. Biology has studied in detail all these types of self-healing of the genetic material of cells.
15. The genetic code is a method of encoding the amino acid sequence of proteins using a sequence of nucleotides, characteristic of all living organisms. The amino acid sequence in a protein molecule is encrypted as a nucleotide sequence in a DNA molecule and is called genetic code. The section of a DNA molecule responsible for the synthesis of one protein is called genome.
DNA uses four nucleotides - adenine (A), guanine (G), cytosine (C), thymine (T), which in Russian literature are designated by the letters A, G, C and T. These letters make up the alphabet of the genetic code. RNA uses the same nucleotides, with the exception of thymine, which is replaced by a similar nucleotide - uracil, which is designated by the letter U (U in Russian literature). In DNA and RNA molecules, nucleotides are arranged in chains and, thus, sequences of genetic letters are obtained.
To build proteins in nature, 20 different amino acids are used. Each protein is a chain or several chains of amino acids in a strictly defined sequence. This sequence determines the structure of the protein, and therefore all its biological properties. The set of amino acids is also universal for almost all living organisms.
The implementation of genetic information in living cells (that is, the synthesis of a protein encoded by a gene) is carried out using two matrix processes: transcription (that is, the synthesis of mRNA on a DNA matrix) and translation of the genetic code into an amino acid sequence (synthesis of a polypeptide chain on an mRNA matrix). Three consecutive nucleotides are sufficient to encode 20 amino acids, as well as the stop signal indicating the end of the protein sequence. A set of three nucleotides is called a triplet. Accepted abbreviations corresponding to amino acids and codons are shown in the figure.
Properties of the genetic code
Triplet - a meaningful unit of code is a combination of three nucleotides (triplet, or codon).
Continuity - there is no punctuation between triplets, that is, the information is read continuously.
Non-overlap - the same nucleotide cannot simultaneously be part of two or more triplets. (Not true for some overlapping genes in viruses, mitochondria, and bacteria that encode multiple frameshift proteins.)
Uniqueness - a certain codon corresponds to only one amino acid. (The property is not universal. The UGA codon in Euplotes crassus encodes two amino acids - cysteine and selenocysteine)
Degeneracy (redundancy) - several codons can correspond to the same amino acid.
Universality - the genetic code works the same in organisms of different levels of complexity - from viruses to humans (genetic engineering methods are based on this) (There are also a number of exceptions to this property, see the table in the “Variations of the standard genetic code” section in this article).
16.Biosynthesis conditions
Protein biosynthesis requires genetic information from the DNA molecule; messenger RNA - the carrier of this information from the nucleus to the place of synthesis; ribosomes - organelles where protein synthesis itself occurs; a set of amino acids in the cytoplasm; transfer RNAs that encode amino acids and transfer them to the site of synthesis on ribosomes; ATP is a substance that provides energy for the encoding and biosynthesis process.
Stages
Transcription- the process of biosynthesis of all types of RNA on a DNA matrix, which occurs in the nucleus.
A certain section of the DNA molecule despirals, the hydrogen bonds between the two chains are destroyed under the action of enzymes. On one DNA strand, as on a template, an RNA copy is synthesized from nucleotides according to the complementary principle. Depending on the DNA section, ribosomal, transport, and messenger RNAs are synthesized in this way.
After mRNA synthesis, it leaves the nucleus and is sent to the cytoplasm to the site of protein synthesis on ribosomes.
Broadcast- the process of synthesis of polypeptide chains carried out on ribosomes, where mRNA is an intermediary in transmitting information about the primary structure of the protein.
Protein biosynthesis consists of a series of reactions.
1. Activation and coding of amino acids. tRNA has the shape of a clover leaf, in the central loop of which there is a triplet anticodon, corresponding to the code for a specific amino acid and the codon on the mRNA. Each amino acid is connected to the corresponding tRNA using the energy of ATP. A tRNA-amino acid complex is formed, which enters the ribosomes.
2. Formation of the mRNA-ribosome complex. mRNA in the cytoplasm is connected by ribosomes on the granular ER.
3. Assembly of the polypeptide chain. tRNA with amino acids, according to the principle of anticodon-codon complementarity, combines with mRNA and enters the ribosome. In the peptide center of the ribosome, a peptide bond is formed between two amino acids, and the released tRNA leaves the ribosome. In this case, the mRNA advances one triplet each time, introducing a new tRNA - an amino acid and removing the released tRNA from the ribosome. The entire process is provided by ATP energy. One mRNA can combine with several ribosomes, forming a polysome, where many molecules of one protein are simultaneously synthesized. Synthesis ends when nonsense codons (stop codes) begin on the mRNA. Ribosomes are separated from mRNA, and polypeptide chains are removed from them. Since the entire synthesis process takes place on the granular endoplasmic reticulum, the resulting polypeptide chains enter the ER tubules, where they acquire their final structure and are converted into protein molecules.
All synthesis reactions are catalyzed by special enzymes with the expenditure of ATP energy. The rate of synthesis is very high and depends on the length of the polypeptide. For example, in the ribosome of Escherichia coli, a protein of 300 amino acids is synthesized in approximately 15-20 seconds.